redis 和缓存
1.redis 数据结构与应用场景
⼀、简介
Redis 是开源免费, key-value 内存数据库,主要解决⾼并发、⼤数据场景下,热点数据访问的性能问题,提供⾼性能的数据快速访问。项⽬中部分数据访问⽐较频繁,对下游 DB(例如 MySQL)造成服务压⼒,这时候可以使⽤缓存来提⾼效率。
Redis 的主要特点包括:
- Redis 数据存储在内存中,可以提高热点数据的访问效率
- Redis 除了支持 key-value 类型的数据,同时还支持其他多种数据结构的存储;
- Redis 支持数据持久化存储,可以将数据存储在磁盘中,机器重启数据将从磁盘重新加载数据;Redis 作为缓存数据库和 MySQL 这种结构化数据库进行对比。
- 从数据库类型上,Redis 是 NoSQL 半结构化缓存数据库,MySQL 是结构化关系型数据库;
- 从读写性能上,MySQL 是持久化硬盘存储,读写速度较楼,Redis 数据存储读取都在内存,同时也可以持久化到磁盘,读写速度较快;
- 从使用场景上,Redis 一般作为 MySQL 数据读取性能优化的技术送型,彼此配合使用。Redis 用于存储热数据或者级存数据,并不存在相互替换的关系。
⼆、Redis 基本数据结构与实战场景
redis 的数据结构可以理解为 Java 数据类型中的 Map<String,Object>,key 是 String 类型,value 是下⾯ 的类型。只不过作为⼀个独⽴的数据库单独存在,所以 Java 中的 Map 怎么⽤,redis 就怎么⽤,⼤同⼩异。
字符串类型的数据结构可以理解为 Map<String,String>
list 类型的数据结构可以理解为 Map<String,List
> set 类型的数据结构可以理解为 Map<String,Set
> hash 类型的数据结构可以理解为 Map<String,HashMap<String,String>>
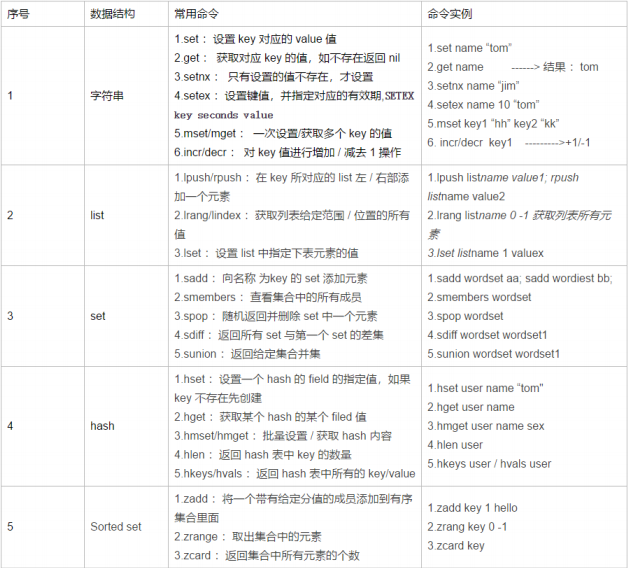
上图中命令行更正:Irange,不是 lrang
三、redis 应用场景解析
3.1 String 类型使用场景
场景一:商品库存数
从业务上,商品库存数据是热点数据,交易行为会直接影响库存。而 Redis 自身 String 类型提供了:
incr key #增加⼀个库存
decr key # 减少⼀个库存
incrby key 10 # 增加20个库存
decrby key 15 # 减少15个库存- set goods_id 10;设置 id 为 goodid 的商品的库存初始值为 10;
- decr goods_id;当商品被购买时候,库存数据减 1。
依此类推的场景:商品的浏览次数,问题或者回复的点赞次数等。这种计数的场景都可以考虑利用 Redis 来实现。
场景二:时效信息存储
Redis 的数据存储具有自动失效能力。也就是存储的 key-value 可以设置过期时间,SETEX mykey 60 “value”中的第 2 个参数就是过期时间。比如,用户登录某个 App 需要获取登录验证码,验证码在 30 秒内有效。
- 生成验证码:生成验证码并使用 String 类型在 reids 存储验证码,同时设置 30 秒的失效时间。如:SETEX validcode 30 “value”
- 验证过程:用户获得验证码之后,我们通过 get validcode 获取验证码,如果获取不到说明验证码过期了。
3.2 List 类型使用场景
list 是按照插入顺序排序的字符串链表。可以在头部和尾部插入新的元素(双向链表实现,两端添加元素的时间复杂度为 O(1))。
场景一:消息队列实现
目前有很多专业的消息队列组件 Kafka、 RabbitMQ 等。我们在这里仅仅是使用 list 的特征来实现消息队列的要求。在实际技术选型的过程中,大家可以慎重思考。list 存储就是一个队列的存储形式:
Ipush key value; 在 key 对应 list 的头部添加字符串元素;
rpop key; 移除列表的最后一个元素,返回值为移除的元素。
场景二:最新上架商品
在交易网站首页经常会有新上架产品推荐的模块,这个模块是存储了最新上架前 100 名。这时候使用 Redis 的 list 数据结构,来进行 TOP 100 新上架产品的存储。Redis trim 指令对一个列表进行修剪(trim),这样 list 就会只包含指定范围的指定元素。
ltrim key start endstart 和 end 都是由 0 开始计数的,这⾥的 0 是列表⾥的第⼀个元素(表头),1 是第⼆个元素。
如下伪代码演示:
//把新上架商品添加到链表⾥
ret = r.lpush("new:goods", goodsId)
//保持链表 100 位
ret = r.ltrim("new:goods", 0, 99)
//获得前 100 个最新上架的商品 id 列表
newest_goods_list = r.lrange("new:goods", 0, 99)3.3 set 类型使用场景
set 也是存储了⼀个集合列表功能。和 list 不同,set 具备去重功能(和 Java 的 Set 数据类型⼀样)。当需要存储⼀个列表信息,同时要求列表内的元素不能有重复,这时候使⽤ set ⽐较合适。与此同时,set 还提供的交集、并集、差集。
例如,在交易⽹站,我们会存储⽤户感兴趣的商品信息,在进⾏相似⽤户分析的时候, 可以通过计算两个不同⽤户之间感兴趣商品的数量来提供⼀些依据。
//userid 为⽤户 ID , goodID 为感兴趣的商品信息。
sadd "user:userId" goodID
sadd "user:101" 1
sadd "user:101" 2
sadd "user:102" 1
sadd "user:102" 3
sinter "user:101" "user:102" # 返回值是1获取到两个⽤户相似的产品, 然后确定相似产品的类⽬就可以进⾏⽤户分析。类似的应⽤场景还有, 社交场景下共同关注好友, 相似兴趣 tag 等场景的⽀持。
3.4 Hash 类型使用场景
Redis 在存储对象(例如:⽤户信息)的时候需要对对象进⾏序列化转换然后存储,还有⼀种形式,就是将对象数据转换为 JSON 结构数据,然后存储 JSON 的字符串到 Redis。对于⼀些对象类型,还有另外⼀种⽐较⽅便的类型,那就是按照 Redis 的 Hash 类型进⾏存储。
hset key field value例如,我们存储⼀些⽹站⽤户的基本信息, 我们可以使⽤:
hset user101 name "⼩明"
hset user101 phone "123456"
hset user101 sex "男"这样就存储了⼀个⽤户基本信息,存储信息有:{name : ⼩明, phone : “123456”,sex : “男”}
当然这种类似场景还⾮常多, ⽐如存储订单的数据,产品的数据,商家基本信息等。⼤家可以参考来进⾏存储选型。但是不适合存储关联关系⽐较复杂的数据,那种场景还得⽤关系型数据库⽐较⽅便。
3.5 Sorted Set 类型使用场景
Redis sorted set 的使⽤场景与 set 类似,区别是 set 不是⾃动有序的,⽽ sorted set 可以通过提供⼀个 score 参数来为存储数据排序,并且是⾃动排序,插⼊既有序。业务中如果需要⼀个有序且不重复的集合列表,就可以选择 sorted set 这种数据结构。⽐如:商品的购买热度可以将购买总量 num 当做商品列表的 score,这样获取最热⻔的商品时就是可以⾃动按售卖总量排好序。
2. 整合单例模式
redis 集群模式和哨兵模式⾼可⽤的安装与运维,需要去专⻔的 redis 课程学习。这⾥主要⾯向 SpringBoot 整合 redis 来开发,不涉及 redis 集群⾼可⽤及运维知识。
⼀、spring-data-redis 简介
Spring Boot 提供了对 Redis 集成的组件包:spring-boot-starter-data-redis,它依赖于 spring-data-redis 和 lettuce。Spring Boot 1.0 默认使⽤的是 Jedis 客户端,2.0 替换成了 Lettuce, spring-boot-starter-data-redis 为我们隔离了其中的差异性。
Lettuce:是⼀个可伸缩线程安全的 Redis 客户端,多个线程可以共享同⼀个 RedisConnection,它 利⽤优秀 Netty NIO 框架来⾼效地管理多个连接。
Spring Data:是 Spring 框架中的⼀个主要项⽬,⽬的是为了简化构建基于 Spring 框架应⽤的数据访问,包括⾮关系数据库、Map-Reduce 框架、云数据服务等,另外也包含对关系数据库的访问⽀持。
Spring Data Redis:是 Spring Data 项⽬中的⼀个主要模块,实现了对 Redis 客户端 API 的⾼度封装,使对 Redis 的操作更加便捷。
⼆、整合 spring data redis
引入依赖包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>引入 commons-pool 2 是因为 Lettuce 需要使用 commons-pool 2 创建 Redis 连接池.
application 全局配置 redis 的单节点实例:
spring:
redis:
database: 0 # Redis 数据库索引(默认为 0)
host: 127.0.0.1 # Redis 服务器地址
port: 6379 # Redis 服务器连接端⼝
password: 123456 # Redis 服务器连接密码(默认为空)
timeout: 5000 # 连接超时,单位ms
lettuce:
pool:
max-active: 8 # 连接池最⼤连接数(使⽤负值表示没有限制) 默认 8
max-wait: -1 # 连接池最⼤阻塞等待时间(使⽤负值表示没有限制) 默认 -1
max-idle: 8 # 连接池中的最⼤空闲连接 默认 8
min-idle: 0 # 连接池中的最⼩空闲连接 默认 03.使用 redisTemplate 操作数据
⼀、redis 模板封装类
RedisTemplate 的封装使我们能够更⽅便的进⾏ redis 数据操作,⽐直接使⽤ Jedis 或者 Lettuce 的 javaSDK 要⽅便很多。RedisTemplate 作为 java 操作 redis 数据库的 API 模板更通⽤,可以操作所有的 redis 数据类型。
// 注⼊RedisTemplate,更通⽤
@Resource
private RedisTemplate<String, Object> redisTemplate;
ValueOperations<String,Object> ValueOperations = redisTemplate.opsForValue();//操作字符串
HashOperations<String, String, Object> hashOperations = redisTemplate.opsForHash();//操作 hash
ListOperations<String, Object> listOperations = redisTemplate.opsForList();//操作 list
SetOperations<String, Object> setOperations = redisTemplate.opsForSet();//操作 set
ZSetOperations<String, Object> zSetOperations = redisTemplate.opsForZSet();//操作有序 setListOperations、ValueOperations、HashOperations、SetOperations、ZSetOperations 等都是针对专有数据类型进⾏操作,使⽤起来更简洁。
@Resource(name = "redisTemplate")
private ValueOperations<String,Object> valueOperations; //以redis string类型存取Java Object(序列化反序列化)
@Resource(name = "redisTemplate")
private HashOperations<String, String, Object> hashOperations; //以redis的hash类型存储java Object
@Resource(name = "redisTemplate")
private ListOperations<String, Object> listOperations; //以redis的list类型 存储java Object
@Resource(name = "redisTemplate")
private SetOperations<String, Object> setOperations; //以redis的set类型存 储java Object
@Resource(name = "redisTemplate")
private ZSetOperations<String, Object> zSetOperations; //以redis的zset类型存储java Object⼆、基础数据 Java 类
为了⽅便后⾯写代码解释 API 的使⽤⽅法,写测试⽤例。我们需要先准备数据对象 Person,注意要实现 Serializable 接⼝,为什么⼀定要实现这个接⼝?我们下⽂解释。
@Data
public class Person implements Serializable {
private static final long serialVersionUID = -8985545025228238754L;
String id;
String firstname;
String lastname;
Address address; //注意这⾥,不是基础数据类型
public Person(String firstname, String lastname) {
this.firstname = firstname;
this.lastname = lastname;
}
}准备数据对象 Address
@Data
public class Address implements Serializable {
private static final long serialVersionUID = -8985545025228238771L;
String city;
String country;
public Address(String city, String country) {
this.city = city;
this.country = country;
}
}三、StringRedisTemplate
除了 RedisTemplate 模板类,还有另⼀个模板类叫做 StringRedisTemplate 。⼆者都提供了⽤来操作 redis 数据库的 API。
@SpringBootTest
public class RedisConfigTest {
@Resource
private StringRedisTemplate stringRedisTemplate; //以String序列化⽅式 保存数据的通⽤模板类
@Resource
private RedisTemplate<String, Person> redisTemplate; //默认以JDK⼆进 制⽅式保存数据的通⽤模板类
@Test
public void stringRedisTemplate() {
Person person = new Person("zhang","san");
person.setAddress(new Address("南京","中国"));
//将数据存⼊redis数据库
stringRedisTemplate.opsForValue().set("player:srt","zhangsan",20,TimeUnit.SECONDS);
redisTemplate.opsForValue().set("player:rt",person,20,TimeUnit.SECONDS);
}
}⼆者的区别在于
操作的数据类型不同,以 List 类型为例:RedisTemplate 操作
List<Object>,StringRedisTemplate 操作List<String>序列化数据的⽅式不同,RedisTemplate 使⽤的是 JdkSerializationRedisSerializer 存⼊数据会将数据先序列化成字节数组然后在存⼊ Redis 数据库。 StringRedisTemplate 使⽤的是 StringRedisSerializer redis 持久化的 java 数据类为什么要实现 Serializable 接⼝?因为 RedisTemplate 默认使⽤的是 JdkSerializationRedisSerializer,也就是使⽤ Java JDK 默认的序列化⽅式存储数据。如果不实现 Serializable 接⼝,JDK 序列化就会报错,这是 java 基础知识。如果我们可以不使⽤ JDK 默认的序列化⽅式,就不需要实现这个 Serializable 接⼝。
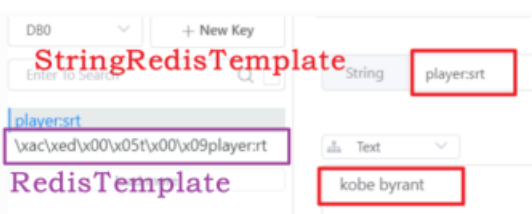
需要注意的是因为 RedisTemplate 和 StringRedisTemplate 的默认序列化存储⽅式不⼀样,所以⼆者存储的数据并不能通⽤。也就是说 RedisTemplate 存的数据只能⽤ RedisTemplate 去取,对于 StringRedisTemplate 也是⼀样。
四、解决 key-value 乱码问题

其实这个不是严格意义上的乱码,是 JDK 的⼆进制序列化之后的存储⽅式。
如何解决?看下⽂的配置类代码
采⽤ StringRedisSerializer 对 key 进⾏序列化(字符串格式)
采⽤ Jackson2JsonRedisSerializer 对 value 将进⾏序列化(JSON 格式)
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate redisTemplate = new RedisTemplate();
redisTemplate.setConnectionFactory(redisConnectionFactory);
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(objectMapper);
//重点在这四⾏代码
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}乱码问题的症结在于对象的序列化问题:RedisTemplate 默认使⽤的是 JdkSerializationRedisSerializer (⼆进制存储),StringRedisTemplate 默认使⽤的是 StringRedisSerializer(redis 字符串格式存储)。
序列化⽅式对⽐:
JdkSerializationRedisSerializer: 使⽤ JDK 提供的序列化功能。 优点是反序列化时不需要提供类型信息(class),但缺点是需要实现 Serializable 接⼝,还有序列化后的结果⾮常庞⼤,是 JSON 格式的 5 倍左右,这样就会消耗 redis 服务器的⼤量内存。⽽且是以⼆进制形式保存,⾃然⼈⽆法理解。
Jackson2JsonRedisSerializer: 使⽤ Jackson 库将对象序列化为 JSON 字符串。优点是速度快,序列化后的字符串短⼩精悍,不需要实现 Serializable 接⼝。似乎没啥缺点。
StringRedisSerializer 序列化之后的结果,⾃然⼈也是可以理解,但是 value 只能是 String 类型,不能是 Object。
五、使用 redisTemplate 存取 redis 各种数据类型
下⾯的各种数据类型操作的 api 和 redis 命令⾏ api 的含义⼏乎是⼀致的。
@SpringBootTest
public class RedisConfigTest2 {
@Resource(name = "redisTemplate")
private ValueOperations<String,Object> valueOperations; //以redis string类型存取Java Object(序列化反序列化)
@Resource(name = "redisTemplate")
private HashOperations<String, String, Object> hashOperations; //以redis的hash类型存储java Object
@Resource(name = "redisTemplate")
private ListOperations<String, Object> listOperations; //以redis的list类型存储java Object
@Resource(name = "redisTemplate")
private SetOperations<String, Object> setOperations; //以redis的set类型存储java Object
@Resource(name = "redisTemplate")
private ZSetOperations<String, Object> zSetOperations; //以redis的zset类型存储java Object
@Test
public void testValueObj() {
Person person = new Person("张","三");
person.setAddress(new Address("南京","中国"));
//向redis数据库保存数据(key,value),数据有效期20秒
valueOperations.set("player:1",person,20, TimeUnit.SECONDS); //20秒之后数据消失
//根据key把数据取出来
Person getBack = (Person)valueOperations.get("player:1");
System.out.println(getBack);
}
@Test
public void testSetOperation() {
Person person = new Person("zhang","san");
Person person2 = new Person("张","三");
setOperations.add("playerset",person,person2); //向Set中添加数据项
//members获取Redis Set中的所有记录
Set<Object> result = setOperations.members("playerset");
System.out.println(result); //包含kobe和curry的数组
}
@Test
public void HashOperations() {
Person person = new Person("kobe","byrant");
//使⽤hash的⽅法存储对象数据(⼀个属性⼀个属性的存,下节教⼤家简单的⽅法)
hashOperations.put("hash:player","firstname",person.getFirstname());
hashOperations.put("hash:player","lastname",person.getLastname());
hashOperations.put("hash:player","address",person.getAddress());
//取出⼀个对象的属性值,有没有办法⼀次将整个对象取出来?有,下节介绍
String firstName = (String)hashOperations.get("hash:player","firstname");
System.out.println(firstName); //kobe
}
@Test
public void ListOperations() {
//将数据对象放⼊队列
listOperations.leftPush("list:player",new Person("张","三"));
listOperations.leftPush("list:player",new Person("张","三丰"));
listOperations.leftPush("list:player",new Person("张","三⻛"));
//从左侧存,再从左侧取,所以取出来的数据是后放⼊的curry
Person person = (Person) listOperations.leftPop("list:player");
System.out.println(person); //curry对象
}
}4. 使用 Redis Repository 操作数据
通过集成 spring-boot-starter-data-redis 之后⼀共有三种 redis hash 数据操作⽅式可以供我们选择
⼀个属性、⼀个属性的存取
使⽤ Jackson2HashMapper 存取对象
使⽤ RedisRepository 的对象操作(本节核⼼内容)
一、一个属性、一个属性的存取
这种⽅式在上⼀节中的代码,已经得以体现。
@Test
public void HashOperations() {
Person person = new Person("zhang","san");
person.setAddress(new Address("南京","中国"));
//使⽤hash的⽅法存储对象数据(⼀个属性⼀个属性的存,下节教⼤家简单的⽅法)
hashOperations.put("hash:player","firstname",person.getFirstname());
hashOperations.put("hash:player","lastname",person.getLastname());
hashOperations.put("hash:player","address",person.getAddress());
String firstName = (String)hashOperations.get("hash:player","firstname");
System.out.println(firstName);
}⼀个 hash 代表⼀个对象的数据
⼀个对象有多个属性 key、value 键值对数据,每⼀组键值对都可以单独存取
⼆、使⽤ Jackson2HashMapper 存取对象
上⼀⼩节我们操作 hash 对象的时候是⼀个属性⼀个属性设置的,那我们有没有办法将对象⼀次性 hash ⼊库呢?可以使⽤ jacksonHashOperations 和 Jackson2HashMapper
@SpringBootTest
@ExtendWith(SpringExtension.class)
public class RedisConfigTest3 {
@Resource(name="redisTemplate")
private HashOperations<String, String, Object> jacksonHashOperations;
//注意这⾥的false,下⽂会讲解
private HashMapper<Object, String, Object> jackson2HashMapper = new Jackson2HashMapper(false);
@Test
public void testHashPutAll(){
Person person = new Person("zhang","san");
person.setId("zhang");
person.setAddress(new Address("洛杉矶","美国"));
//将对象以hash的形式放⼊redis数据库
Map<String,Object> mappedHash = jackson2HashMapper.toHash(person);
jacksonHashOperations.putAll("player:" + person.getId(), mappedHash);
//将对象从数据库取出来
Map<String,Object> loadedHash = jacksonHashOperations.entries("player:" + person.getId());
Object map = jackson2HashMapper.fromHash(loadedHash);
Person getback = new ObjectMapper().convertValue(map,Person.class);
//Junit5,验证放进去的和取出来的数据⼀致
assertEquals(person.getFirstname(),getback.getFirstname());
}
}使⽤这种⽅式可以⼀次性存取 Java 对象为 redis 数据库的 hash 数据类型。需要注意的是:执⾏上⾯的测试⽤例,Person 和 Address ⼀定要有 public ⽆参构造⽅法,在将 map 转换成 Person 或 Address 对象的时候⽤到,如果没有的话会报错。
三、使⽤ RedisRepository 的对象操作
使⽤ RedisRepository 进⾏ redis 数据操作,它不只是能简单地存取数据,还可以做很多 CURD 操作。使⽤起来和⽤ JPA 进⾏关系型数据库的单表操作,⼏乎是⼀样的。
⾸先,我们需要在需要操作的 java 实体类上⾯加上@RedisHash 注解,并使⽤@Id 为该实体类指定 id。
@RedisHash("people") //注意这⾥的person,下⽂会说明
public class Person {
@Id
String id;
//其他和上⼀节代码⼀样
}然后写⼀个 PersonRepository ,继承 CrudRepository,是不是也和 JPA 差不多?
//泛型第⼆个参数是id的数据类型
public interface PersonRepository extends CrudRepository<Person, String> {
// 继承CrudRepository,获取基本的CRUD操作
}CrudRepository 默认为我们提供了下⾯的这么多⽅法,我们直接调⽤就可以了。
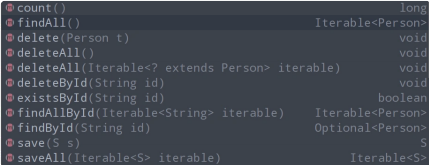
然后进⾏下⾯的测试
@SpringBootTest
@ExtendWith(SpringExtension.class)
public class RedisRepositoryTest {
@Resource
PersonRepository personRepository;
@Test
public void test(){
Person rand = new Person("zhang", "san");
rand.setAddress(new Address("南京", "中国"));
//存
personRepository.save(rand);
//取
Optional<Person> op = personRepository.findById(rand.getId());
Person p2 = op.get();
//统计Person的数量
personRepository.count();
//删除person对象rand
personRepository.delete(rand);
}
}测试结果:需要注意的是 RedisRepository 在存取对象数据的时候,实际上使⽤了 redis 的 2 种数据类型
第⼀种是 Set 类型,⽤于保存每⼀个存⼊ redis 的对象(Person)的 id。我们可以利⽤这个 Set 实现 person 对象集合类的操作,⽐如说:count()统计 redis 数据库中⼀共保存了多少个 person。
第⼆种是 Hash 类型,是⽤来保存 Java 对象的,id 是 RedisRepository 帮我们⽣成的。
5. spring cache 缓存基本用法
一、为什么要做缓存
提升性能绝⼤多数情况下,关系型数据库 select 查询是出现性能问题最⼤的地⽅。⼀⽅⾯,select 会有很多像 join、group、order、like 等这样丰富的语义,⽽这些语义是⾮常耗性能的;另⼀⽅⾯,⼤多数应⽤都是读多写少,所以加剧了慢查询的问题。分布式系统中远程调⽤也会耗很多性能,因为有⽹络开销,会导致整体的响应时间下降。为了挽救这样的性能开销,在业务允许的情况(不需要太实时的数据)下,使⽤缓存是⾮常必要的事情。
缓解数据库压⼒当⽤户请求增多时,数据库的压⼒将⼤⼤增加,通过缓存能够⼤⼤降低数据库的压⼒。
⼆、常⽤缓存操作流程
使⽤缓存最关键的⼀点就是保证:缓存与数据库的数据⼀致性,该怎么去做?下图是⼀种最常⽤的缓存操作模式,来保证数据⼀致性。
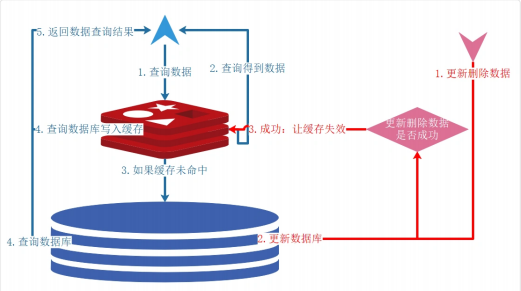
更新写数据:先把数据存到数据库中,然后再让缓存失效或更新。缓存操作失败,数据库事务回滚。
删除写数据: 先从数据库⾥⾯删掉数据,再从缓存⾥⾯删掉。缓存操作失败,数据库事务回滚。
查询读数据
- 缓存命中:先去缓存 cache 中取数据,取到后返回结果。
- 缓存失效:应⽤程序先从 cache 取数据,没有得到,则从数据库中取数据,成功后,在将数据放到缓存中。
如果上⾯的这些更新、删除、查询操作流程全都由程序员通过编码来完成的话
因为加⼊缓存层,程序员的编码量⼤⼤增多
缓存层代码和业务代码耦合,造成难以维护的问题。
三、整合 Spring Cache
我们可以使⽤ Spring cache 解决上⾯遇到的两个问题,Spring cache 通过注解的⽅式来操作缓存,⼀定程度上减少了程序员缓存操作代码编写量。注解添加和移除都很⽅便,不与业务代码耦合,容易维护。
第⼀步:pom.xml 添加 Spring Boot 的 jar 依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>第⼆步:添加⼊⼝启动类 @EnableCaching 注解开启 Caching
在 Spring Boot 中通过@EnableCaching 注解⾃动化配置合适的缓存管理器(CacheManager),SpringBoot 根据下⾯的顺序去侦测缓存提供者,也就是说 Spring Cache ⽀持下⾯的这些缓存框架:
Generic
JCache (JSR-107) (EhCache 3, Hazelcast, Infinispan, and others)
EhCache 2.x
Hazelcast
Infinispan
Couchbase
Redis
Caffeine
Simple
四、在 ArticleController 类上实现一个简单的例子
第⼀次访问⾛数据库,第⼆次访问就⾛缓存了, 可以⾃⼰打⽇志试⼀下。
@Cacheable(value="article")
@GetMapping( "/article/{id}")
public @ResponseBody AjaxResponse getArticle(@PathVariable Long id) {
}使⽤ redis 缓存,被缓存的对象(函数返回值)有⼏个⾮常需要注意的点:
必须实现⽆参的构造函数
需要实现 Serializable 接⼝和定义 serialVersionUID (因为缓存需要使⽤ JDK 的⽅式序列化和反序列化)。
五、更改 Redis 缓存的序列化方式
让缓存使⽤ JDK 默认的序列化和反序列化⽅式⾮常不友好,我们可以修改为使⽤ JSON 序列化与反序列化的⽅式,可读性更强,体积更⼩,速度更快。
@Configuration
public class RedisConfig {
//这个函数是上⼀节的内容
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate redisTemplate = new RedisTemplate();
redisTemplate.setConnectionFactory(redisConnectionFactory);
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(objectMapper);
//重点在这四⾏代码
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
//本节的重点配置,让Redis缓存的序列化⽅式使⽤
redisTemplate.getValueSerializer()
//不在使⽤JDK默认的序列化⽅式
@Bean
public RedisCacheManager redisCacheManager(RedisTemplate redisTemplate) {
RedisCacheWriter redisCacheWriter = RedisCacheWriter.nonLockingRedisCacheWriter(redisTemplate.getConnectionFactory());
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig()
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(redisTemplate.getValueSerializer()));
return new RedisCacheManager(redisCacheWriter, redisCacheConfiguration);
}
}


