整合数据库开发框架
1. 整合 Spring JDBC 操作数据
⼀、JDBC 简介
JDBC(Java DataBase Connectivity)是⼀种⽤于执⾏ SQL 语句的 Java API ,可以为多种关系数 据库提供统⼀访问,它由⼀组⽤ Java 语⾔编写的类和接⼝组成。JDBC 提供了⼀种基准,据此可以 构建更⾼级的⼯具和接⼝,使数据库开发⼈员能够编写数据库应⽤程序。
什么是持久层:持久层就是指对数据进⾏持久化操作的代码,⽐如将数据保存到数据库、⽂件、 磁盘等操作都是持久层操作。所谓持久就是保存起来的意思。对于 web 应⽤最常⽤的持久层框架就是 JDBC、Mybatis、JPA。
⼆、使⽤ JDBC 操作数据库的步骤
直接在 Java 程序中使⽤ JDBC ⽐较复杂,需要 7 步才能完成数据库的操作:
- 加载数据库驱动
- 建⽴数据库连接
- 创建数据库操作对象
- 定义操作的 SQL 语句
- 执⾏数据库操作
- 获取并操作结果集
- 关闭对象,回收资源
关键代码如下:
try {
// 1、加载数据库驱动
Class.forName(driver);
// 2、获取数据库连接
conn = DriverManager.getConnection(url, username, password);
// 3、获取数据库操作对象
stmt = conn.createStatement();
// 4、定义操作的 SQL 语句
String sql = "SELECT * FROM t_user WHERE id = 1 ";
// 5、执⾏数据库操作
rs = stmt.executeQuery(sql);
// 6、获取并操作结果集
while (rs.next()) {
// 解析结果集
}
} catch (Exception e) {
// ⽇志信息
} finally {
// 7、关闭资源
}可以看出直接使⽤ JDBC 来操作数据库⽐较复杂。
为此,Spring Boot 针对 JDBC 的使⽤提供了对应的 Starter 包:spring-boot-starter-jdbc,它 其实就是在 Spring JDBC 上做了进⼀步的封装,⽅便在 Spring Boot ⽣态中更好的使⽤ JDBC。
SpringBoot JDBC 参考: https://www.yiibai.com/springjdbc
不论是 JDBC,还是封装之后的 Spring JDBC,直接操作数据库都⽐较麻烦,实际开发不建议直接 使⽤ JDBC 操作数据库。
三、 将 Spring JDBC 集成到 Spring boot 项⽬
第⼀步:引⼊ Maven 依赖包,包括 Spring JDBC 和 MySQL 驱动。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>第⼆步:修改 application.yml,增加数据库连接、⽤户名、密码相关的配置。 driver-class-name 根据⾃⼰使⽤的数据库和数据库版本准确填写。
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/spring_boot?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: ****
password: ****
driver-class-name: com.mysql.cj.jdbc.Drivermysql-connector-java 5.5 版本及其以下,使⽤ com.mysql.jdbc.Driver
mysql-connector-java 5.7 版本及以上,使⽤ com.mysql.cj.jdbc.Driver
四、 spring boot jdbc 基础代码
spring jdbc 集成完毕之后,我们来写代码做⼀个基本的测试。
⾸先我们新建⼀张测试表 t_article
CREATE TABLE `t_article` (
`id` INT(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`author` VARCHAR(32) NOT NULL COMMENT '作者',
`title` VARCHAR(32) NOT NULL COMMENT '标题',
`content` VARCHAR(512) NOT NULL COMMENT '内容',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
)
COMMENT='⽂章'
ENGINE=InnoDB;DAO 层代码:
- jdbcTemplate.update 适合于 insert 、update 和 delete 操作
- jdbcTemplate.queryForObject ⽤于查询单条记录返回结果
- jdbcTemplate.query ⽤于查询结果列表
- BeanPropertyRowMapper 可以将数据库字段的值向 Article 对象映射,满⾜驼峰标识也可以⾃动映射。如:数据库 create_time 字段映射到 createTime 属性。
@Repository //持久层依赖注⼊注解
public class ArticleJDBCDAO {
@Resource
private JdbcTemplate jdbcTemplate;
//保存⽂章
public void save(Article article) {
//jdbcTemplate.update适合于insert 、update和delete操作;
jdbcTemplate.update("INSERT INTO article(author,title,content,create_time) values(?, ?, ?, ?)",
article.getAuthor(),
article.getTitle(),
article.getContent(),
article.getCreateTime());
}
//删除⽂章
public void deleteById(Long id) {
//jdbcTemplate.update适合于insert 、update和delete操作;
jdbcTemplate.update("DELETE FROM article WHERE id = ?",id);
}
//更新⽂章
public void updateById(Article article) {
//jdbcTemplate.update适合于insert 、update和delete操作;
jdbcTemplate.update("UPDATE article SET author = ?, title = ?,content = ?,create_time = ? WHERE id = ?",
article.getAuthor(),
article.getTitle(),
article.getContent(),
article.getCreateTime(),
article.getId());
}
//根据id查找⽂章
public Article findById(Long id) {
//queryForObject⽤于查询单条记录返回结果
return (Article) jdbcTemplate.queryForObject("SELECT * FROM article WHERE id=?",
new Object[]{id},new BeanPropertyRowMapper<>(Article.class));
}
//查询所有
public List<Article> findAll(){
//query⽤于查询结果列表
return (List<Article>) jdbcTemplate.query("SELECT * FROM article", new BeanPropertyRowMapper<>(Article.class));
}
}service 层接⼝
public interface ArticleService {
void saveArticle(Article article);
void deleteArticle(Long id);
void updateArticle(Article article);
Article getArticle(Long id);
List<Article> getAll();
}service 层操作 JDBC 持久层
@Slf4j
@Service //服务层依赖注⼊注解
public class ArticlleJDBCService implements ArticleService {
@Resource
private
ArticleJDBCDAO articleJDBCDAO;
@Transactional
public void saveArticle( Article article) {
articleJDBCDAO.save(article);
//int a = 2/0; //⼈为制造⼀个异常,⽤于测试事务
return article;
}
public void deleteArticle(Long id){
articleJDBCDAO.deleteById(id);
}
public void updateArticle(Article article){
articleJDBCDAO.updateById(article);
}
public Article getArticle(Long id){
return articleJDBCDAO.findById(id);
}
public List<Article> getAll(){
return articleJDBCDAO.findAll();
}
}最后,在之前的 ArticleController 中调⽤ ArticleRestJDBCService 实现⽅法,进⾏从 Controller 到 Service 到 DAO 层的全流程测试。
- 重点测试⼀下事务的回滚,⼈为制造⼀个被除数为 0 的异常。
- 在 saveArticle ⽅法上使⽤了@Trasactional 注解,该注解基本功能为事务管理,保证 saveArticle ⽅法⼀旦有异常,所有的数据库操作就回滚。
2. 主流 ORM 持久层框架选型
⼀、现状描述
⽬前 Java 持久层 ORM 框架应⽤最⼴泛的就是 JPA 和 Mybatis。JPA 只是⼀个 ORM 框架的规范, 对该 规范的实现⽐较完整就是 Spring Data JPA(底层基于 Hibernate 实现),是基于 Spring 的数据持久 层框架,也就是说它只能⽤在 Spring 环境内。
Mybatis 也是⼀个优秀的数据持久层框架,能⽐较好的⽀持 ORM 实体关系映射、动态 SQL 等。 为什么国内的开发⼈员或者开发团队较少使⽤ JPA ?国内某度指数搜索如下。
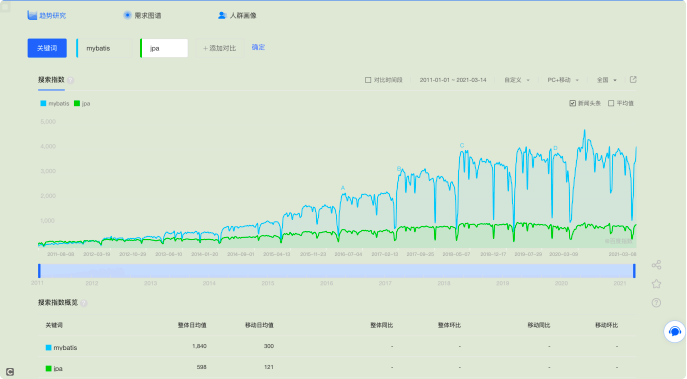
图中蓝⾊线条为 Mybatis 搜索量,绿⾊为 JPA 搜索量。如果换⼀个国外的搜索指数,你会得到⼀个完全不同的结果。
这是为什么呢?我们还要从 JPA 的特点说起:
- JPA 对于单表的或者简单的 SQL 查询⾮常友好,甚⾄可以说⾮常智能。它为你准备好了⼤量拿来 即⽤的持久层操作⽅法。甚⾄只要写 findByName 这样⼀个接⼝⽅法,就能智能的帮你执⾏根据 名称查找实体类对应的表数据,完全不⽤写 SQL 。
- 但是,JPA 对于多表关联查询以及动态 SQL 、⾃定义 SQL 等⾮常不友好。对于 JPA 来说,⼀种实 现实现⽅式是 QueryDSL ,实现的代码是下⾯这样的。
你希望⽤这样的代码代替 SQL 么?
JPAQueryFactory queryFactory = new JPAQueryFactory(em);
JPAQuery<Tuple> jpaQuery = queryFactory.select(QTCity.tCity,QTHotel.tHotel)
.from(QTCity.tCity)
.leftJoin(QTHotel.tHotel)
.on(QTHotel.tHotel.city.longValue().eq(QTCity.tCity.id.longValue()));
//添加查询条件
jpaQuery.where(predicate);
//拿到结果
return jpaQuery.fetch();另⼀种⽅法是使⽤ NativeQuery ,你希望在 Java 代码⾥⾯⽤拼字符串的⽅式写 SQL 么?
@Entity
@NamedNativeQueries(value={
@NamedNativeQuery(
name = "studentInfoById",
query = " SELECT * FROM student_info "
+ " WHERE stu_id = ? ",
resultClass = Student.class
)
})
@Table(name="student_info")以上的这部分实现还没有考虑到动态 SQL 的问题,如果考虑到动态 SQL ,写法会更复杂。
**所谓的动态 SQL 就是:根据传⼊参数条件的不同,构造不同的 SQL **,很多的⽐较这两个框架的⽂章 都忽略了动态 SQL 的问题,这⽅⾯ Mybatis ⽀持的更好。Mybatis 写的动态 SQL 说到底还是 SQL ,⽽ 不是 Java 代码或者 Java 代码拼字符串。
程序员特别排斥⼏件事:
- 将复杂关联关系的 SQL 写在 Java 代码⾥⾯,拼串书写不⽅便
- SQL 是最能表达实体关系查询的语⾔,程序员不希望使⽤异化 SQL 语⾔
- 程序员不希望学习不通⽤的东⻄,显然 SQL ⼤家都会
- JPA 虽然将⼤部分操作封装起来了,挺好⽤的,但是 SQL 调优怎么做?
⼆、孰优孰劣?
然⽽,另外有⼀派观点,看⼈家国外的程序员怎么都⽤ JPA ?JPA 使⽤很⽅便啊,唯⼀缺点就是复杂 关联 SQL ⽀持差⼀点,但是只要你学⼀下也还可以⽀持啊,你们这是劣币驱逐良币。如果经过很好的实体关系模型的设计,JPA 显然是最优解,程序员写的 SQL 还真不如 JPA 根据实体关系⽣成的 SQL 。
- ⾸先,国外程序员习惯使⽤ JPA 的⼀个原因,真的是因为他们国家的应⽤规模太⼩了,⽐起国内 的⼀个应⽤动则上百万的⽤户相⽐,他们在数据库设计与调优的需求上显然更从容。
- 国外的应⽤设计往往更简洁,⽽国内的应⽤需求往往功能性更强。可以去看看⼯作流,什么会签、流程回退什么的都是我们发明的,他们没有。你让他们⽤ JPA 写⼀个我们的⼯作流应⽤试⼀试,累吐⾎他们也做不到。
- 异化 SQL 或者代码⾥⾯写 SQL,⼀定程度上增加了学习成本和使⽤成本。所以⽤的⼈少,⽤的⼈少你就得迁就团队中的⼤部分⼈。
说完以上⼏点,Mybatis 为什么在国内会有如此多的使⽤者及使⽤⼚商就不难理解了。Mybatis 还可 以使⽤如:Mybatis-plus 或者代码⾃动⽣成来弥补易⽤性上的不⾜。JPA 的身材、家室、性格样样 都是满分,就是脸⻓得磕碜点难以处理社交关系。Mybatis 虽说在各⽅⾯都不优秀,身材还可以、样 貌也还说得过去、性格也还好。关键是你说什么都听你的,还有愿意帮他化妆的朋友。要你说你选 哪⼀个?
那么,有的⼈会说,你这是抬杠?国外就没有受众数量多、功能性强的互联⽹应⽤了么?恐怕⽐国 内还多吧,这个也是事实。但是从⽐例上讲还是国内更多,⽐例决定开发⼈员选择技术的⽅向。这 也导致了⼀个惯性思维,他们平时就⽤ JPA 学习训练,所以写⼤型服务应⽤的时候也⽤ JPA 。那么, 他们写 JPA 会写复杂 SQL 么?答案是很少会⽤到,甚⾄有的国外公司就明令禁⽌写关联查询 SQL 。 那怎么办?不⽤关联 SQL 怎么开发业务需求?不会啊。
三、服务拆分或微服务
国内现在有越来越多的公司,进⾏微服务的落地,然⽽真正落地⽐较好的企业少之⼜少。这和多表 关联查询有什么关系?我们先来实现这样⼀个需求:根据⽤户 id 去查询该⽤户所具有的权限。

- 如果我们开发的是传统的单体应⽤,把 user ⽤户表、role ⻆⾊表、auth 权限表进⾏关联查询,然后得到查询结果。
- 如果我们做的是微服务接⼝,我们可能是先去根据⽤户 id 查询⽤户信息,在通过⽤户信息查询该⽤户的⻆⾊信息、最后通过⻆⾊信息查询权限信息。并且每⼀次调⽤ SQL 都可能是⼀个单独的 HTTP 服务接⼝。
那么有的⼈会说,访问多个接⼝⼀定⽐访问⼀个接⼝更慢吧!这个真的不⼀定。如果我们做微服 务,⼀定是我们的应⽤规模及数据量到达了⼀定程度。也⼀定会考虑分表分库、负载均衡、服务拆分细化等问题,当分布式的开发⽅式被应⽤越多,多表关联查询使⽤的机会也就越少。拆分后的服 务由于功能单⼀、负载分流、数据分库存储量级更⼩等原因,访问速度往往⽐⼤数据量数据集中存储、多服务集中部署的应⽤会更快。
问题回来了,不⽤关联 SQL 怎么开发程序?总的来说就是通过合理的服务拆分、数据库拆分、应⽤的界⾯数据的组织关系的合理的设计,团队拥有⽐较好的微服务落地经验,是可以实现不使⽤关联查询 SQL 开发应⽤的。⼤家也知道,NOSQL 越来越流⾏,绝⼤部分的 NOSQL 数据库都没有所谓的 关联关系。
四、框架对⽐选型
| 对⽐项 | Spring Data JPA | Mybatis |
|---|---|---|
| 单表操作⽅式 | 只需继承,代码量极少,⾮常⽅便。⽽且⽀持⽅法名⽤关键字⽣成 SQL | 可以使⽤代码⽣成⼯具或 Mybatis-Plus 等⼯具,也很⽅便,但相对 JPA 要弱⼀些。 |
| 多表关联查询 | 不太友好,动态 SQL 使⽤不够⽅便,⽽且 SQL 和代码耦合到⼀起 | 友好,可以有⾮常直观的动态 SQL |
| ⾃定义 SQL | SQL 写在注解⾥⾯,写动态 SQL 有些费劲 | SQL 可以写在 XML ⾥⾯,是书写动态 SQL 语法利器。也⽀持注解 SQL 。 |
| 学习成本 | 略⾼ | 较低 ,基本会写 SQL 就会⽤ |
总结:
- 如果你是⾃⼰开发“⼩⽽美”的应⽤,建议你使⽤ JPA
- 如果你是开发⼤⽽全的企业级应⽤,当然要遵从团队的技术选型。这个技术选型在国内通常是 Mybatis 。
- 如果你们公司的管理⾮常规范,微服务落地经验也⾮常成熟,可以考虑在团队项⽬中使⽤ JPA 。 少⽤或不⽤关联查询。
3. Java bean 的赋值转换
⼀、为什么要做 Java bean 赋值转换
在实际的开发过程中,由于业务的复杂性,通常并不能做到⼀个 model 实体贯穿持久层、服务层、 控制层。通常需要进⾏实体对象 java bean 的赋值转换。

PO: persistent object 持久对象,对应数据库中的 entity。通常在进⾏数据库数据存取操作时使⽤。可以简单的认为⼀个 PO 对应数据库中⼀张表中的⼀个记录。PO 对象⾥⾯只有基本数据类型和 String 类型的属性(如:int、String),与数据库字段是⼀⼀对应的。
BO: business object 业务对象,业务对象主要作⽤是把业务逻辑封装为⼀个对象。这个对象可以包括⼀个或多个其它的对象。通常⼀个 BO 是多个 PO 的组合体,⽐如:PO 在查询出来之后,需要经过业务处理,处理过程中对象的属性逐渐变复杂,有嵌套的数组,对象数组等等。
VO: view object,主要与 web ⻚⾯的展示结构相对应,所以 VO 也是前端与后端的数据交换定义。
下图中是⼀个 VO,⽤于返回给前端 Web 界⾯,⽤于渲染的数据内容:

下图是⼀个 PO,⽤于对数据库表的数据的存取。
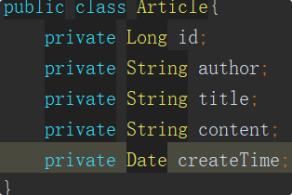
注意看⼆者的区别,⼀个 AricleVO 不仅包含了 Article 的数据,还包含了 Reader 读者的数据。
- 当你需要向数据库⾥⾯插⼊数据的时候,需要将 Article(PO) 和 Reader(PO) 分别作为 PO 记录插 ⼊数据库。
- 当你需要将⼀篇⽂章的数据和读者信息返回给⻚⾯做渲染的时候,需要从数据库⾥⾯查询 Article(PO) 和 Reader(PO) ,然后将⼆者组合映射转换为 AricleVO 返回给前端。
如果你的业务可以⽤⼀个实体类对象,就可以贯穿持久层到展现层,就没有必要做映射赋值转换, 也没有必要去分 VO、BO、PO。⽐如:单表表格数据展现、修改、新增。
⼆、BeanUtils 和 Dozer?
⽐较常⽤的 JavaBean 赋值转换⼯具是 BeanUtils 和 Dozer ,如果没有 BeanUtils 和 Dozer 帮我们进⾏对象之间的转换赋值,我们会怎么做?
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class User {
private Integer id;
private String phone;
private String password;
private String avatar;
private Date createTime;
}
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class Book {
private Integer id;
private String name;
}
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class UserVo {
private Integer id;
private String phone;
private String password;
private String avatar;
private Date createTime;
private List<Book> books;
}
@Test
void beanCopyTest() {
User user= User.builder()
.id(1)
.phone("180****4983")
.password("123")
.avatar("1.jpg")
.createTime(new Date())
.build();
UserVo userVo = new UserVo();
userVo.setId(user.getId());
userVo.setPhone(user.getPhone());
userVo.setPassword(user.getPassword());
userVo.setAvatar(user.getAvatar());
userVo.setCreateTime(user.getCreateTime());
log.info(String.valueOf(userVo));
}BeanUtils 是 Spring Boot 内⾃动集成的 JavaBean ⾃动转换⼯具( apache 项⽬下也有⼀个 BeanUtils,这⾥专指 Spring 包下⾯的 BeanUtils),使⽤⾮常⽅便。可以通过下⾯的⽅法将 user(PO) 转换为 userVo 。
@Test
void beanUtilsTest() {
User user = User.builder().id(1).phone("180****4983").password("123").avatar("1.jpg")
.createTime(new Date()).build();
UserVo userVo = new UserVo();
//是Spring的BeanUtils,不是apache的
BeanUtils.copyProperties(user, userVo);
log.info(String.valueOf(userVo));
}dozer 是⼀个能把实体和实体之间进⾏转换的⼯具
只要建⽴好映射关系,就像是 ORM 的数据库和实体映射⼀样。
dozer 的功能⽐ BeanUtils 功能更强⼤,但是 BeanUtils 的性能更好。所以简单的同名同类型属性赋值转换使⽤ BeanUtils ,复杂的级联结构的属性赋值转换使⽤ Dozer 。
- Dozer 可以实现 Integer 、Long 等基础类型与 String 数据类型的属性之间的转换(只要名字相同 就可以了,数据类型可以不同),BeanUtils 只能做到同数据类型同名的属性之间赋值。
- Dozer 可以实现递归级联结构的对象赋值,BeanUtils(Spring 包下⾯的)也可以。
- Dozer 可以实现复杂的数据转换关系,通过 xml 配置的⽅式,BeanUtils 做不到。
使⽤⽅法示例如下
引⼊依赖
<dependency>
<groupId>com.github.dozermapper</groupId>
<artifactId>dozer-spring-boot-starter</artifactId>
<version>6.5.2</version>
</dependency>@Test
void dozerTest1() {
User user = User.builder().id(1).phone("180****4983").password("123").avatar("1.jpg")
.createTime(new Date()).build();
Mapper mapper = DozerBeanMapperBuilder.buildDefault();
// user(PO) -> userVo
UserVo userVo = mapper.map(user, UserVo.class);
System.out.println(userVo);
}这段示例代码将 PO 对象 user ,转换为 VO 对象 userVo ,转换过程将所有同名同类型的数据⾃动赋值给 userVo 的成员变量,当然除了 books (因为 PO ⾥⾯没有 books 数组数据)。
转换属性之间的映射,默认是根据属性名称来匹配的。
三、引⼊ Dozer(6.5.2)
从 6.2.0 版本开始,dozer 官⽅为我们提供了 dozer-spring-boot-starter ,这样我们在 spring boot ⾥⾯使⽤ dozer 更⽅便了。
<dependency>
<groupId>com.github.dozermapper</groupId>
<artifactId>dozer-spring-boot-starter</artifactId>
<version>6.5.2</version>
</dependency>在实际开发中,可能不只需要 PO 转 VO ,有时还需要 List<PO>转 List<VO> 写⼀个⼯具类,封装 Dozer 实现对象互转,List 互转
package top.syhan.boot.orm.util;
import com.github.dozermapper.core.Mapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.lang.NonNull;
import org.springframework.lang.Nullable;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import javax.annotation.Resource;
import java.util.Collections;
import java.util.List;
import java.util.Optional;
import java.util.stream.Collectors;
/**
* @description: dozer转换类
* @author: syhan
* @date: 2022-03-28
**/
@Component
public class DozerUtils {
/**
* dozer转换的核⼼mapper对象
*/
private static Mapper dozerMapper;
@Resource
private Mapper mapper;
@PostConstruct
private void construct() {
DozerUtils.setDozerMapper(mapper);
}
private static void setDozerMapper(Mapper dozerMapper) {
DozerUtils.dozerMapper = dozerMapper;
}
/**
* 转换实体为另⼀个指定的实体
* 任意⼀个参数为NULL时 会抛出NPE
* {@link com.github.dozermapper.core.util.MappingValidator#validateMappingRequest}
*
* @param source 源实体 不能为NULL
* @param clazz ⽬标实体 不能为NULL
* @param <T> 泛型
* @return 转换后的结果
*/
@NonNull
public static <T> T convert(@NonNull Object source, @NonNull Class<T> clazz) {
return dozerMapper.map(source, clazz);
}
/**
* 转换List实体为另⼀个指定的实体
* source如果为NULL 会使⽤空集合
* 在⽬标实体为NULL时 会抛出NPE
* {@link com.github.dozermapper.core.util.MappingValidator#validateMappingRequest}
*
* @param source 源集合 可以为NULL
* @param clazz ⽬标实体 不能为NULL
* @param <T> 泛型
* @return 转换后的结果
*/
@Nullable
public static <T> List<T> convert(@Nullable List<?> source, @NonNull Class<T> clazz) {
return Optional.ofNullable(source)
.orElse(Collections.emptyList())
.stream()
.map(bean -> dozerMapper.map(bean, clazz))
.collect(Collectors.toList());
}
}四、⾃定义类型转换(⾮对称类型转换)
在平时的开发中,我们的 VO 和 PO 的同名字段尽量是类型⼀致的。
String 属性-> String 属性,Date 属性 -> Date 属性,但是也不排除由于最开始的设计失误。
- 需要 String 属性 -> Date 属性,或者 ClassA 转 ClassB 呢?这种我们该如何实现呢?
- 或者需要 createDate 转 cDate 这种属性名称都不⼀样的,怎么做。
⽐如下⾯的两个测试 model ,进⾏属性⾃动赋值转换映射。
@Data
@AllArgsConstructor
public class TestA{
public String name;
public String createDate; //注意这⾥名称不⼀样,类型不⼀样
}
@Data
@NoArgsConstructor
public class TestB{
public String name;
public Date cDate; //注意这⾥名称不⼀样,类型不⼀样
}然后我们需要⾃⼰去创建转换对应关系,⽐如:resources/dozer/dozer-mapping.xml。
xml 内容看上去复杂,其实核⼼结构很简单。就是 class-a 到 classb 的转换,filed ⽤来定义特殊字段 (名称或类型不⼀致)。configuration 可以做全局的配置,date-format 对所有的⽇期字符串转换 ⽣效。
<?xml version="1.0" encoding="UTF-8"?>
<mappings xmlns="http://dozermapper.github.io/schema/bean-mapping"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://dozermapper.github.io/schema/beanmapping
https://dozermapper.github.io/schema/bean-mapping.xsd">
<configuration>
<date-format>yyyy-MM-dd HH:mm:ss</date-format>
</configuration>
<mapping>
<class-a>top.syhan.boot.orm.dozer.TestA</class-a>
<class-b>top.syhan.boot.orm.dozer.TestB</class-b>
<field>
<a>createDate</a>
<b>cDate</b>
</field>
</mapping>
</mappings>然后把 dozer 转换配置⽂件通知 application.yml ,进⾏加载⽣效。
dozer:
mapping-files: classpath:/dozer/dozer-mapping.xml这样⼀个对象⾥⾯有 String 属性到 Date 属性转换的时候,就会⾃动应⽤这个转换规则, 不再报错。
@Test
void dozerTest3() {
Mapper mapper = DozerBeanMapperBuilder.create().withMappingFiles("dozer/dozermapping.xml").build();
TestA testA = new TestA("zhangsan", "2022-03-28 12:12:12");
System.out.println(mapper.map(testA, TestB.class));
}输出:
TestB(name=zhangsan, cDate=FRI Mar 17 12:12:12 CST 2022)4. 整合 Spring Data JPA
⼀、 Sping Data JPA 简介
Spring Data JPA 是 Spring 基于 ORM 框架、JPA 规范的基础上封装的⼀套 JPA 应⽤框架,底层使⽤了 Hibernate 的 JPA 技术实现,可使开发者⽤极简的代码即可实现对数据的访问和操作。它提供了包括增删改查等在内的常⽤功能接⼝,且易于扩展。
学习并使⽤ Spring Data JPA 可以极⼤提⾼开发效率。
由于微服务系统的⼴泛应⽤,服务粒度逐渐细化,多表关联查询的场景⼀定程度减少。
单表查询和单表的数据操作正是 JPA 的优势。
⼆、 将 Spring Data JPA 集成到 Spring Boot
第⼀步:引⼊ maven 依赖包,包括 Spring Data JPA 和 Mysql 的驱动
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>第⼆步:修改 application.yml ,配置好数据库连接和 jpa 的相关配置
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/spring_boot?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: ****
password: ******
driver-class-name: com.mysql.cj.jdbc.Driver
# ⾃动创建、更新、验证数据库表结构
jpa:
properties:
hibernate:
hbm2ddl:
auto: update
show-sql: truespring.jpa.database-platform=org.hibernate.dialect.MySQL5InnoDBDialectHibernate 创建数据库表的时候,默认使⽤的数据库存储引擎是 MyISAM ,这个参数作⽤是在建表的时候,将存储引擎切换为 InnoDB 。
spring.jpa.show-sql=true在⽇志中打印出执⾏的 SQL 语句信息。spring.jpa.properties.hibernate.hbm2ddl.auto是 hibernate 的配置属性,其主要作⽤是:⾃动根据实体类的定义创建、更新、验证数据库表结构。所以这个参数是⼀个⽐较危 险的参数,使⽤的时候⼀定要注意。该参数的⼏种配置如下:create:每次加载 hibernate 时都会删除上⼀次的⽣成的表,然后根据你的 model 类再重 新来⽣成新表,哪怕两次没有任何改变也要这样执⾏,这就是导致数据库表数据丢失的⼀个 重要原因。create-drop:每次加载 hibernate 时根据 model 类⽣成表,但是 sessionFactory ⼀关闭,表就⾃动删除。update:最常⽤的属性,第⼀次加载 hibernate 时根据 model 类会⾃动建⽴起表的结构 (前提是先建⽴好数据库),以后加载 hibernate 时根据 model 类⾃动更新表结构,即使表结构改变了但表中的⾏仍然存在不会删除以前的⾏。要注意的是当部署到服务器后,表结构是不会被⻢上建⽴起来的,是要等应⽤第⼀次运⾏起来后才会。validate:每次加载hibernate时,验证创建数据库表结构,只会和数据库中的表进⾏⽐较,不会创建新表,但是会插⼊新值。
作为⼀个谨慎的程序员,应永远
将
spring.jpa.properties.hibernate.hbm2ddl.auto的值设置为 validate 。在⽣产 环境上的任何⼀次配置失误都可能导致数据库表结构变化甚⾄ drop 数据丢失。可能有⼈会觉得 JPA(hibernate) 的这种⽅式⾃动建表更新表结构,⾯向程序员很友好,但是在⽣ 产环境下这是最不友好的⽅式。表还是要通过模型去设计、通过 SQL 去创建,尽量不要⽤这种根据 model 类⽣成数据库表结构的⽅式。
三、 基础核⼼⽤法
我们来实现⼀个简单的使⽤ JPA 操作数据库的例⼦。
3.1 实体 Model 类
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
@Entity
@Table(name="article")
public class Article {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Long id;
@Column(nullable = false,length = 32)
private String author;
@Column(nullable = false, unique = true,length = 32)
private String title;
@Column(length = 512)
private String content;
private Date createTime;
}@Entity必选注解,表示这个类是⼀个实体类,接受 JPA 控制管理,对应数据库中的⼀个表。@Table可选注解,指定这个类对应数据库中的表名。如果这个类名和数据库表名符合驼峰及下划线规则,可以省略这个注解。如 FlowType 类名对应表名 flow_type。@Id指定这个字段为表的主键。@GeneratedValue(strategy=GenerationType.IDENTITY)指定主键的⽣成⽅式,⼀般主键为⾃增的话,就采⽤ GenerationType.IDENTITY 的⽣成⽅式@Column注解针对⼀个字段,对应表中的⼀列。nullable = false 表示数据库字段不能为空, unique = true 表示数据库字段不能有重复值, length = 32 表示数据库字段最⼤程度为 32。
关于更多注解的详细⽤法,请参考:# Hibernate Annotations 参考⽂档
3.2 数据操作接⼝
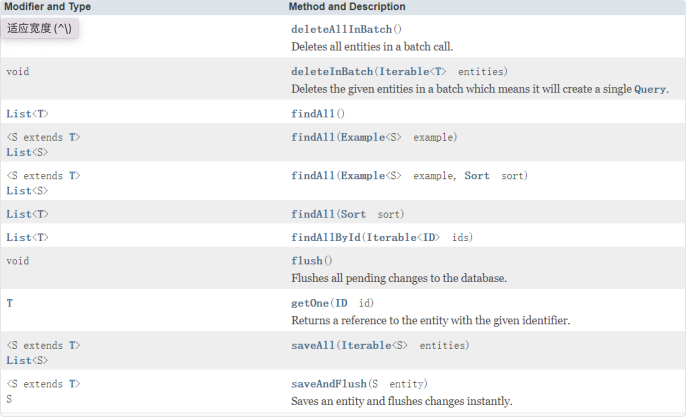
public interface ArticleRepository extends JpaRepository<Article,Long> {
}XxxRepository 继承 JpaRepository 为我们提供了各种针对单表的数据操作⽅法:增删改查,通过调⽤接⼝的⽅法名称就能知道⽅法是做什么操作的。
四、写⼀个服务层调⽤的例⼦
4.1 service 层接⼝
定义⼀个 service 层接⼝
public interface ArticleRestService {
ArticleVO saveArticle(ArticleVO article);
void deleteArticle(Long id);
void updateArticle(ArticleVO article);
ArticleVO getArticle(Long id);
List<ArticleVO> getAll();
}4.2 service 层接⼝实现
@Service
public class ArticleJPARestService implements ArticleRestService {
//将JPA仓库对象注⼊
@Resource
private ArticleRepository articleRepository;
@Resource
private Mapper dozerMapper;
public ArticleVO saveArticle( ArticleVO article) {
Article articlePO = dozerMapper.map(article,Article.class);
//保存⼀个对象到数据库,insert
articleRepository.save(articlePO);
return article;
}
@Override
public void deleteArticle(Long id) {
//根据id删除1条数据库记录
articleRepository.deleteById(id);
}
@Override
public void updateArticle(ArticleVO article) {
Article articlePO = dozerMapper.map(article,Article.class);
//更新⼀个对象到数据库,仍然使⽤save⽅法,实际是根据articlePO.id去update
articleRepository.save(articlePO);
}
@Override
public ArticleVO getArticle(Long id) {
Optional<Article> article = articleRepository.findById(id);
//根据id查找⼀条数据
return dozerMapper.map(article.get(),ArticleVO.class);
}
@Override
public List<ArticleVO> getAll() {
List<Article> articleLis = articleRepository.findAll();
//查询article表的所有数据
return DozerUtils.mapList(articleLis,ArticleVO.class);
}
}注意:虽然新增和修改都是使⽤的 save ⽅法,但是完成的功能是不⼀样的。当保存的对象有主键 id 的时候,save ⽅法会根据 id 更新记录;当保存的对象没有主键 id 的时候,save ⽅法会向数据库⾥⾯ insert ⼀条记录。
可以在控制层调⽤⼀下 service 层⽅法,⽤ postman 测试⼀下。
五、关键字查询接⼝
除了 JpaRepository 为我们提供的增删改查的⽅法。我们还可以⾃定义⽅法,使⽤起来⾮常简单, 甚⾄可以说是强⼤。把下⾯的⽅法名放到 ArticleRepository ⾥⾯,它就⾃动为我们实现了通过 author 字段查找 article 表的所有数据。也就是说,我们使⽤了 find(查找) 关键字, JPA 就⾃动将⽅法 名为我们解析成数据库 SQL 操作,太智能了。
//注意这个⽅法的名称,jPA会根据⽅法名⾃动⽣成SQL执⾏
Article findByAuthor(String author);等同于
SELECT *
FROM article
WHERE author = ?其他具体的关键字,使⽤⽅法和⽣产成 SQL 如下表所示
| 关键字 | 接口函数例子 | JPQL 片段 |
|---|---|---|
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is,Equals | findByFirstnameIs,findByFirstn ameEquals | … where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ? 1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age ⇐ ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull | findByAgeIsNull | … where x.age is null |
| IsNotNull,NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection ages) | … where x.lastname <> ?1 |
| NotIn | findByAgeNotIn(Collection age) | … where x.age not in ?1 |
| TRUE | findByActiveTrue() | … where x.active = true |
| FALSE | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstame) = UPPER(?1) |
可以看到我们这⾥没有任何类 SQL 语句就完成了两个条件查询⽅法。
这就是 Spring-data-jpa 的⼀⼤特性:通过解析⽅法名创建查询。
针对单表的数据查询简单到令⼈发指,怎么可以这么简单,照这个趋势发展,程序员早晚失业。
六、测试关键字查询
@RunWith(SpringRunner.class)
@SpringBootTest
public class JPAKeyWordTest {
@Resource
private ArticleRepository articleRepository;
@Test
public void userTest() {
Article article = articleRepository.findByAuthor("mqxu");
System.out.println(article);
}
}七、其他
spring-data-jpa 的能⼒远不⽌这些,不建议使⽤ Query、NamedQuery、Specification、 QueryDSL 等,如果你⽤这些东⻄,还不如⾃⼰写 SQL。
可参考下⽅⽂档进⾏更深⼊的学习:
5. 整合 Mybatis
⼀、数据库和数据表
建表脚本
/*
Navicat Premium Data Transfer
Source Server : local_conn
Source Server Type : MySQL
Source Server Version : 80026
Source Host : localhost:3306
Source Schema : spring_boot
Target Server Type : MySQL
Target Server Version : 80026
File Encoding : 65001
Date: 28/03/2022 07:50:23
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for t_teacher 教师表:和班级表⼀对⼀
-- ----------------------------
DROP TABLE IF EXISTS `t_teacher`;
CREATE TABLE `t_teacher` (
`teacher_id` int NOT NULL AUTO_INCREMENT COMMENT '教师id',
`teacher_name` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '教师姓名',
`clazz_id` int NOT NULL COMMENT '教师管理的班级id',
PRIMARY KEY (`teacher_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_general_ci ROW_FORMAT=DYNAMIC;
-- ----------------------------
-- Records of t_teacher
-- ----------------------------
BEGIN;
INSERT INTO `t_teacher` VALUES (1, '许⽼师', 1);
INSERT INTO `t_teacher` VALUES (2, '张⽼师', 2);
COMMIT;
SET FOREIGN_KEY_CHECKS = 1;
-- ----------------------------
-- Table structure for t_clazz 班级表:和教师表⼀对⼀,和学⽣表⼀对多
-- ----------------------------
DROP TABLE IF EXISTS `t_clazz`;
CREATE TABLE `t_clazz` (
`clazz_id` int NOT NULL AUTO_INCREMENT COMMENT '班级id',
`clazz_name` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '班级名称',
`teacher_id` int NOT NULL COMMENT '班级管理⽼师的id',
PRIMARY KEY (`clazz_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_general_ci ROW_FORMAT=DYNAMIC;
-- ----------------------------
-- Records of t_clazz
-- ----------------------------
BEGIN;
INSERT INTO `t_clazz` VALUES (1, '后端开发班', 1);
INSERT INTO `t_clazz` VALUES (2, '前端开发班', 2);
COMMIT;
-- ----------------------------
-- Table structure for t_student 学⽣表:和班级表多对⼀,和课程表多对多
-- ----------------------------
DROP TABLE IF EXISTS `t_student`;
CREATE TABLE `t_student` (
`student_id` int NOT NULL AUTO_INCREMENT COMMENT '学⽣id',
`clazz_id` int NOT NULL COMMENT '学⽣所属班级的id',
`student_name` varchar(50) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '学⽣姓名',
`hometown` varchar(100) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '学⽣籍贯',
`birthday` date DEFAULT NULL COMMENT '出⽣⽇期',
PRIMARY KEY (`student_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=3010 DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_general_ci ROW_FORMAT=DYNAMIC;
-- ----------------------------
-- Records of t_student
-- ----------------------------
BEGIN;
INSERT INTO `t_student` VALUES (1001, 1, '钱智康', '江苏苏州', '2000-01-18');
INSERT INTO `t_student` VALUES (1002, 1, '李智康', '江苏⽆锡', '2000-02-18');
INSERT INTO `t_student` VALUES (1003, 1, '张智康', '江苏常州', '2000-03-18');
INSERT INTO `t_student` VALUES (1004, 1, '王智康', '江苏南京', '2000-04-18');
INSERT INTO `t_student` VALUES (1005, 1, '孙志康', '江苏徐州', '2001-05-18');
INSERT INTO `t_student` VALUES (1006, 2, '周志康', '江苏泰州', '2001-06-18');
INSERT INTO `t_student` VALUES (1007, 2, '郭志康', '江苏扬州', '2001-07-18');
INSERT INTO `t_student` VALUES (1008, 2, '陈志康', '江苏盐城', '2001-08-18');
COMMIT;
-- ----------------------------
-- Table structure for t_course 课程表:和学⽣表多对多
-- ----------------------------
DROP TABLE IF EXISTS `t_course`;
CREATE TABLE `t_course` (
`course_id` int NOT NULL AUTO_INCREMENT COMMENT '课程id',
`course_name` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '课程名称',
PRIMARY KEY (`course_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=20003 DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_general_ci ROW_FORMAT=DYNAMIC;
-- ----------------------------
-- Records of t_course
-- ----------------------------
BEGIN;
INSERT INTO `t_course` VALUES (20001, '后端⼯程化开发');
INSERT INTO `t_course` VALUES (20002, '前端⼯程化开发');
COMMIT;⼆、加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>三、写配置
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/spring_boot?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
mybatis:
# 指定相应接⼝对应的xml⽂件所在⽬录
mapper-locations:
classpath:mapper/*.xml
# 实体类所在包
type-aliases-package: com.mqxu.boot.orm.mybatis.domain
configuration:
# mybatis开启驼峰式命名
map-underscore-to-camel-case: true四、综合示例
以教师、班级、学⽣、课程等为例,来做⼀个综合的例⼦
Student.java
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class Student {
/**
* 学⽣id
*/
private Integer studentId;
/**
* 学⽣所属班级的id
*/
private Integer clazzId;
/**
* 学⽣姓名
*/
private String studentName;
/**
* 学⽣籍贯
*/
private String hometown;
/**
* 出⽣⽇期
*/
private LocalDate birthday;
}StudentMapper.java
public interface StudentMapper {
/**
* 新增学⽣
*
* @param student student对象
* @return int
*/
int insert(Student student);
/**
* 根据id删除学⽣
*
* @param studentId 学⽣id
* @return int
*/
int deleteByPrimaryKey(Integer studentId);
/**
* 根据id查询学⽣
*
* @param studentId 学⽣id
* @return 查询到的学⽣对象
*/
Student selectByPrimaryKey(Integer studentId);
/**
* 修改学⽣信息
*
* @param student student对象
* @return int
*/
int updateByPrimaryKeySelective(Student student);
/**
* 批量新增学⽣
*
* @param students 学⽣集合
* @return int
*/
int batchInsert(@Param("students") List<Student> students);
/**
* 批量删除
*
* @param idList 待删记录id集合
* @return int
*/
int batchDelete(@Param("idList") List<Integer> idList);
/**
* 批量修改
*
* @param students 学⽣集合
* @return int
*/
int batchUpdate(@Param("students") List<Student> students);
/**
* 按条件单表查询,结合动态SQL
*
* @param student 参数对象
* @return List<Student>
*/
List<Student> selectByDynamicSql(Student student);
}StudentMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="top.mqxu.springboot.mybatis.mapper.StudentMapper">
<resultMap id="BaseResultMap" type="Student">
<id column="student_id" jdbcType="INTEGER" property="studentId"/>
<result column="clazz_id" jdbcType="INTEGER" property="clazzId"/>
<result column="student_name" jdbcType="VARCHAR" property="studentName"/>
<result column="hometown" jdbcType="VARCHAR" property="hometown"/>
<result column="birthday" jdbcType="DATE" property="birthday"/>
</resultMap>
<sql id="Base_Column_List">
`student_id`,
`clazz_id`,
`student_name`,
`hometown`,
`birthday`
</sql>
<insert id="insert" keyColumn="student_id" keyProperty="studentId" parameterType="top.syhan.springboot.mybatis.domain.Student" useGeneratedKeys="true">
insert into `t_student` (`clazz_id`, `student_name`, `hometown`, `birthday`)
values (#{clazzId,jdbcType=INTEGER}, # {studentName,jdbcType=VARCHAR}, #{hometown,jdbcType=VARCHAR},
#{birthday,jdbcType=DATE})
</insert>
<select id="selectByPrimaryKey" parameterType="java.lang.Integer" resultMap="BaseResultMap">
select
<include refid="Base_Column_List"/>
from `t_student`
where `student_id` = #{studentId,jdbcType=INTEGER}
</select>
<delete id="deleteByPrimaryKey" parameterType="java.lang.Integer">
delete
from `t_student`
where `student_id` = #{studentId,jdbcType=INTEGER}
</delete>
<update id="updateByPrimaryKeySelective" parameterType="Student">
update `t_student`
<set>
<if test="clazzId != null">
`clazz_id` = #{clazzId,jdbcType=INTEGER},
</if>
<if test="studentName != null">
`student_name` = #{studentName,jdbcType=VARCHAR},
</if>
<if test="hometown != null">
`hometown` = #{hometown,jdbcType=VARCHAR},
</if>
<if test="birthday != null">
`birthday` = #{birthday,jdbcType=DATE},
</if>
</set>
where `student_id` = #{studentId,jdbcType=INTEGER}
</update>
<insert id="batchInsert" parameterType="Student">
insert into t_student values
<foreach collection="students" item="student" index="index" separator=",">
(#{student.studentId}, #{student.clazzId}, #{student.studentName}, #{student.hometown}, #{student.birthday})
</foreach>
</insert>
<delete id="batchDelete" parameterType="int">
delete
from t_student
where student_id in
<foreach collection="idList" item="item" index="index" open="("separator="," close=")">
#{item}
</foreach>
</delete>
<update id="batchUpdate" parameterType="java.util.List">
<foreach collection="students" item="item" index="index" open="" close="" separator=";">
update t_student t
<set>
<if test="item.clazzId != null">
`clazz_id` = #{item.clazzId,jdbcType=INTEGER},
</if>
<if test="item.studentName != null">
`student_name` = #{item.studentName,jdbcType=VARCHAR},
</if>
<if test="item.hometown != null">
`hometown` = #{item.hometown,jdbcType=VARCHAR},
</if>
<if test="item.birthday != null">
`birthday` = #{item.birthday,jdbcType=DATE},
</if>
</set>
where t.student_id = #{item.studentId}
</foreach>
</update>
<select id="selectByDynamicSql" parameterType="Student" resultType="Student">
select *
from t_student
where 1 = 1
<choose>
<when test="clazzId != null">
and clazz_id = #{clazzId}
</when>
<when test="hometown != null">
and hometown like "%"#{hometown}"%"
</when>
</choose>
</select>
</mapper>StudentMapperTest.java
package top.syhan.springboot.mybatis.mapper;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit.jupiter.SpringExtension;
import top.mqxu.springboot.mybatis.domain.Student;
import javax.annotation.Resource;
import java.time.LocalDate;
import java.util.ArrayList;
import java.util.List;
import static org.junit.jupiter.api.Assertions.assertEquals;
@SpringBootTest
@ExtendWith(SpringExtension.class)
class StudentMapperTest {
@Resource
private StudentMapper studentMapper;
@Test
void insert() {
Student student = Student.builder()
.clazzId(1)
.studentName("test学⽣")
.hometown("江苏南京")
.birthday(LocalDate.of(2000, 10, 10))
.build();
int n = studentMapper.insert(student);
assertEquals(n, 1);
}
@Test
void deleteByPrimaryKey() {
}
@Test
void selectByPrimaryKey() {
Student student = studentMapper.selectByPrimaryKey(1);
assertEquals("⾦晨星", student.getStudentName());
}
@Test
void updateByPrimaryKeySelective() {
Student student = Student.builder()
.studentId(1009)
.clazzId(2)
.studentName("新名字")
.build();
int n = studentMapper.updateByPrimaryKeySelective(student);
assertEquals(1, n);
}
@Test
void batchInsert() {
List<Student> students = new ArrayList<>();
for (int i = 0; i < 10; i++) {
Student student = Student.builder()
.studentId(3000 + i)
.clazzId(1)
.studentName("测试学⽣" + i)
.hometown("测试城市")
.birthday(LocalDate.of(1999, 10, 10))
.build();
students.add(student);
}
int n = studentMapper.batchInsert(students);
assertEquals(10, n);
}
@Test
void batchUpdate() {
List<Student> students = new ArrayList<>();
for (int i = 0; i < 10; i++) {
Student student = Student.builder()
.studentId(3000 + i)
.clazzId(1)
.studentName("新名字" + i)
.build();
students.add(student);
}
int n = studentMapper.batchUpdate(students);
assertEquals(1, n);
}
@Test
void batchDelete() {
List<Integer> idList = new ArrayList<>();
idList.add(3001);
idList.add(3002);
idList.add(3003);
int n = studentMapper.batchDelete(idList);
assertEquals(3, n);
}
@Test
void selectByDynamicSql() {
Student student = Student.builder().hometown("江").build();
List<Student> students = studentMapper.selectByDynamicSql(student);
System.out.println(students);
}
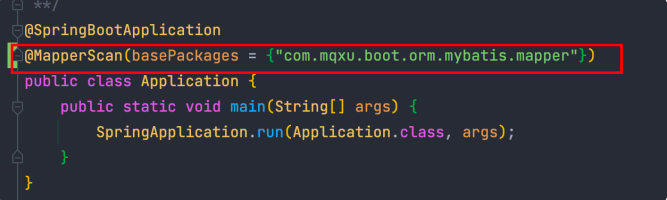
}重要提醒!
- 启动主类不要忘记加注解
- 配置⽂件的数据库连接串如下添加,让它⽀持批量操作

五、Mybatis 关联查询
1、⼀对⼀
教师和班级
- 在⼀⽅声明另⼀⽅的对象,暂时以教师作为主导⽅,反过来也⼀样
package top.syhan.boot.orm.mybatis.domain;
import java.io.Serial;
import java.io.Serializable;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.ibatis.type.Alias;
/**
* @author syhan
* @TableName t_teacher
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
@Alias("Teacher")
public class Teacher implements Serializable {
@Serial
private static final long serialVersionUID = 1L;
/**
* 教师id
*/
private Integer teacherId;
/**
* 教师姓名
*/
private String teacherName;
/**
* 教师管理的班级id
*/
private Integer clazzId;
/**
* 教师管理的班级对象
*/
private Clazz clazz;
public String printInfo() {
return this.teacherId + "," + this.teacherName;
}
}- TeacherMapper.java 接⼝声明查询⽅法
package top.syhan.boot.orm.mybatis.mapper;
import top.syhan.boot.orm.mybatis.domain.Teacher;
/**
* @author syhan
* @description 针对表【t_teacher】的数据库操作Mapper
* @createDate 2022-03-27 21:54:00
* @Entity com.mqxu.boot.orm.mybatis.domain.Teacher
*/
public interface TeacherMapper {
/**
* 根据id查询教师信息(⼀对⼀,关联查询出其管理的班级对象信息)
*
* @param teacherId 教师id
* @return 教师对象
*/
Teacher selectOneByOne(int teacherId);
}- TeacherMapper.xml 实现⼀对⼀关联查询
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="top.syhan.boot.orm.mybatis.mapper.TeacherMapper">
<resultMap id="teacherMap" type="Teacher">
<id column="teacher_id" property="teacherId"/>
<result column="teacher_name" property="teacherName"/>
<association property="clazz" javaType="Clazz">
<id column="clazz_id" property="clazzId"/>
<result column="clazz_name" property="clazzName"/>
</association>
</resultMap>
<select id="selectOneByOne" resultMap="teacherMap" parameterType="int">
SELECT *
FROM t_teacher t,
t_clazz c
WHERE t.teacher_id = #{teacherId}
AND t.clazz_id = c.clazz_id
</select>
</mapper>- TeacherMapperTest 测试
package top.syhan.boot.orm.mybatis.mapper;
import top.syhan.boot.orm.mybatis.domain.Teacher;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit.jupiter.SpringExtension;
import javax.annotation.Resource;
import static org.junit.jupiter.api.Assertions.*;
/**
* @description:
* @author: syhan
* @date: 2022-03-28
**/
@SpringBootTest
@ExtendWith(SpringExtension.class)
@Slf4j
class TeacherMapperTest {
@Resource
private TeacherMapper teacherMapper;
@Test
void selectOneByOne() {
Teacher teacher = teacherMapper.selectOneByOne(1);
log.info(teacher.printInfo() + teacher.getClazz().printInfo());
}
}2、⼀对多
班级和学⽣
- ⼀⽅(Clazz)声明多⽅(Student)的集合
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Data
public class Clazz {
/**
* 班级id
*/
private Integer clazzId;
/**
* 班级名称
*/
private String clazzName;
/**
* 班级管理老师的id
*/
private Integer teacherId;
/**
* 一方里声明多方的集合
*/
private List<Student> students;
}- ClazzMapper.java 接⼝
public interface CLazzMapper {
/**
* 根据班级id查询班级
*
* @param clazzId 班级id
* @return 查询到的班级对象
*/
Clazz getClazzOneToMany(int clazzId);
}- ClazzMapper.xml 实现⼀对多关联查询
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="top.syhan.boot.orm.mybatis.mapper.ClazzMapper">
<resultMap id="clazzMap" type="Clazz">
<id column="clazz_id" property="clazzId" jdbcType="INTEGER"/>
<result column="clazz_name" property="clazzName" jdbcType="VARCHAR"/>
<collection property="students" ofType="Student">
<id column="student_id" property="studentId"/>
<result column="student_name" property="studentName"/>
<result column="hometown" property="hometown"/>
</collection>
</resultMap>
<select id="findOneToMany" resultMap="clazzMap">
SELECT c.clazz_id, c.clazz_name, s.student_id, s.student_name, s.hometown
FROM t_clazz c,
t_student s
WHERE c.clazz_id = #{clazzId}
AND c.clazz_id = s.clazz_id
</select>
</mapper>- 测试
3、多对⼀
学⽣和班级
- 多⽅⾥声明⼀⽅的对象
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Data
public class Student {
/**
* 学生id
*/
private Integer studentId;
/**
* 学生所属班级的id
*/
private Integer clazzId;
/**
* 学生姓名
*/
private String studentName;
/**
* 学生籍贯
*/
private String hometown;
/**
* 出生日期
*/
private LocalDate birthday;
/**
* 在多方里,声明一方的对象
*/
private Clazz clazz;
}- StudentMapper 接⼝
public interface StudentMapper {
/**
* 根据学生id查询(关联查询出所属班级信息)
*
* @param studentId 学生id
* @return student学生
*/
Student getStudentManyToOne(int studentId);
}- StudentMapper.xml 实现多对⼀关联查询
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="top.syhan.boot.orm.mybatis.mapper.StudentMapper">
<resultMap id="studentMap" type="Student">
<id column="student_id" property="studentId"/>
<result column="student_name" property="studentName"/>
<result column="hometown" property="hometown"/>
<association property="clazz" javaType="Clazz">
<id column="clazz_name" property="clazzName"/>
<result column="clazz_name" property="clazzName"/>
</association>
</resultMap>
<select id="getStudentManyToOne" resultMap="studentMap" parameterType="int">
SELECT s.student_id, s.student_name, s.hometown, c.clazz_id, c.clazz_name
FROM t_student s,
t_clazz c
WHERE s.student_id = #{clazzId}
AND s.clazz_id = c.clazz_id
</select>
</mapper>- 测试
@Test
void getStudentManyToOne() {
Student student = studentMapper.getStudentManyToOne(1001);
assertEquals(1001, student.getStudentId());
assertEquals("张三", student.getStudentName());
assertEquals(1, student.getClazz().getClazzId());
}4、综合
1) 查询班级信息
班级和教师存在⼀对⼀关系,同时⼜和学⽣存在⼀对多关系
在查询⼀个班级的时候,同时关联查询出班级教师信息、班级所有学⽣信息
Clazz.java
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Data
public class Clazz {
/**
* 班级id
*/
private Integer clazzId;
/**
* 班级名称
*/
private String clazzName;
/**
* 班级管理老师的id
*/
private Integer teacherId;
/**
* 管理班级的教师对象(一对一)
*/
private Teacher teacher;
/**
* 一方里声明多方的集合(一对多)
*/
private List<Student> students;
}- ClazzMapper.java
public interface ClazzMapper {
/**
* 根据班级id查询班级
*
* @param clazzId 班级id
* @return 查询到的班级对象(班级自身信息、班级教师信息、班级所有学生的信息)
*/
Clazz getClazz(int clazzId)
}- ClazzMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="top.syhan.boot.orm.mybatis.mapper.ClazzMapper">
<resultMap id="clazzMap" type="Clazz">
<id column="clazz_id" property="clazzId"/>
<result column="clazz_name" property="clazzName"/>
<association property="teacher" javaType="Teahcer">
<id column="teacher_id" property="teacherId"/>
<result column="teacher_name" property="teacherName"/>
</association>
<collection property="students" ofType="Student">
<id column="student_id" property="studentId"/>
<result column="student_name" property="studentName"/>
<result column="hometown" property="hometown"/>
</collection>
</resultMap>
<select id="getClazz" resultMap="clazzMap" parameterType="int">
SELECT c.clazz_id, c.clazz_name, t.teacher_name, s.student_id, s.student_name, s.hometown
FROM t_clazz c
LEFT JOIN t_teacher t
ON c.clazz_id = t.clazz_id
LEFT JOIN t_student s
ON c.clazz_id = s.clazz_id
WHERE c.clazz_id = #{clazzId}
</select>
</mapper>- 测试
@SpringBootTest
@ExtendWith(SpringExtension.class)
class ClazzMapperTest {
@Resource
private ClazzMapper clazzMapper;
@Test
void getClazz() {
Clazz clazz = clazzMapper.getClazz(1);
assertEquals("软件2126", clazz.getClazzName());
assertEquals(1, clazz.getClazzId());
assertEquals(1, clazz.getTeacher().getTeacherId());
assertEquals("许老师", clazz.getTeacher().getTeacherName());
assertEquals(12, clazz.getStudents().size());
System.out.println("班级信息:");
System.out.println(clazz.getClazzId() + "," + clazz.getClazzName());
System.out.println("班级教师信息:");
System.out.println(clazz.getTeacher().getTeacherId() + "," + clazz.getTeacher().getTeahcerName());
System.out.println("班级学生:");
clazz.getStudents().forEach(student -> System.out.println(student.getStudentName() + "," + student.getHometown()));
}
}2) 查询学⽣信息
学⽣和班级存在多对⼀关系,同时⼜和课程存在多对多关系
在查询⼀个学⽣的时候,同时关联查询出该学⽣所在班级信息、以及学⽣选的所有课程信息
- Student.java 实体类
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Data
public class Student {
/**
* 学生所属班级的id
*/
private Integer clazzId;
/**
* 学生姓名
*/
private String studentName;
/**
* 学生籍贯
*/
private String hometown;
/**
* 出生日期
*/
private LocalDate birthday;
/**
* 学生和班级多对一
*/
private Clazz clazz;
/**
* 学生和课程多对多
*/
private List<Course> courses;
}- StudentMapper.java 接⼝
public interface StudentMapper {
/**
* 根据学生id查询(关联查询出所属班级信息,所选课程信息)
*
* @param studentId 学生id
* @return student对象
*/
Student getStudent(int studentId);
}- StudentMapper.xml 实现
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="top.syhan.boot.orm.mybatis.mapper.StudentMapper">
<resultMap id="studentMap" type="Student">
<id column="student_id" property="studentId"/>
<result column="student_name" property="studentName"/>
<result column="hometown" property="hometown"/>
<association property="clazz" javaType="Clazz">
<id column="clazz_name" property="clazzName"/>
<result column="clazz_name" property="clazzName"/>
</association>
<collection property="courses" ofType="Course">
<id column="course_id" property="courseId"/>
<result column="course_name" property="courseName"/>
</collection>
</resultMap>
<select id="getStudent" resultMap="studentMap" parameterType="int">
SELECT s.student_id, s.student_name, s.hometown, s.birthday, c.clazz_id, c.clazz_name, cc.course_id, cc.course_name
FROM t_student s
LEFT JOIN t_clazz c
ON s.clazz_id = c.clazz_id
LEFT JOIN t_course_student ts
ON s.student_id = ts.student_id
LEFT JOIN t_course cc
ON ts.course_id = cc.course_id
WHERE s.student_id = #{studentId}
</select>
</mapper>- 测试
@Test
void getStudentManyToOne() {
Student student = studentMapper.getStudent(1001);
System.out.println(student);
assertEquals(1001, student.getStudentId());
assertEquals("张三", student.getStudentName());
assertEquals(1, student.getClazz().getCLazzId());
assertEquals("软件2126", student.getClazz().getClazzName());
assertEquals(2, student.getCourses().size());
}


